Ahri-珊
看了下git的数据结构,对一些常用的指令进行了简单的分析。
git 数据结构
1.blob(数据块)
每个blob代表一个(版本的)文件。文件名取自内容的哈希值(文件内容不变不会生成新的blob)。
2.tree(树结构)
一个文件目录。文件的内容为blob对象以及该文件的权限。
3.commit
记录当前提交对应的tree对象、提交信息、父commit。
4.tag、HEAD、branch(引用)
标记某个commit。
创建一个提交
步骤1:修改文件。修改后的文件保存在工作区。
步骤2:执行git add操作,每一个修改的文件在暂存区生成对应的blob对象。
步骤3:执行git commit,首先根据暂存区的blob对象、基于当前指向的commit(a)的tree生成一个新的tree,然后生成一个新的commit对象(b),记录新的tree以及提交信息。最后将当前HEAD指向commit(b),commit(b)的父commit指向commit(a)。
命令本质
分析上一篇博客中提到的git指令实际做的事。
git commit –amend
这个命令创建了一个新的commit对象,因此我们可以编辑他的提交信息,与git commit不同的是新的commit(b)的父commit与commit(a)的父commit相同。执行这个命令不会删除commit(a),可以用git reflog找到commit(a)。
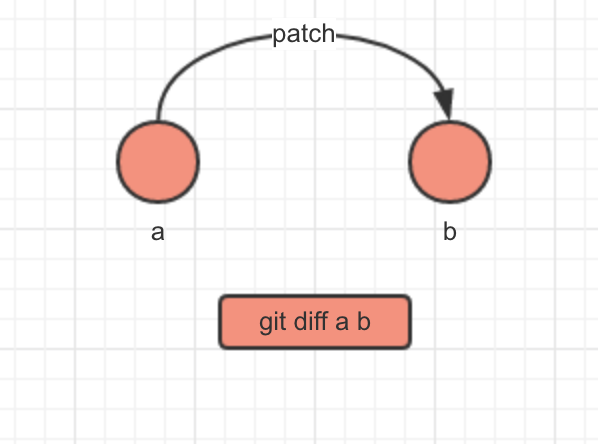
git diff
git diff命令比较了a、b中tree的差异,并产生一个patch文件记录b较与a的更改。
git checkout
将HEAD指向指定的commit。
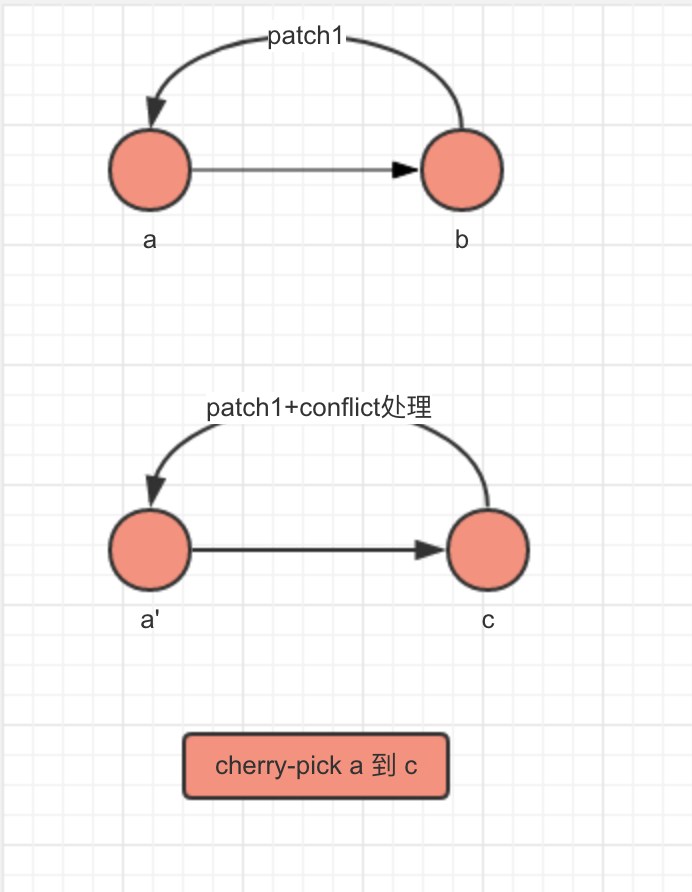
git cherry-pick
1.将a与其父commit(b) diff,生成一个patch文件。
2.将这个patch文件apply到当前HEAD指向的commit(c),即生成一个新的commit对象(a1),a1使用a的提交信息,a1中的tree对象根据c的tree以及patch文件得到,具体就是对c的tree进行patch文件中表示的修改,如果双方都做了更改,就会产生conflict,我们需要修改对应文件,生成一个新的blob对象(比如,patch文件中表明修改文件a某行的hahahaha为hehehehe,但是c的tree对应的文件那一行不是hahahaha,而是dadadada,那这行到底要变成hehehehe还是dadadada就要你自己判断了)。
3.将当前HEAD指向a1,a1的父commit指向c。
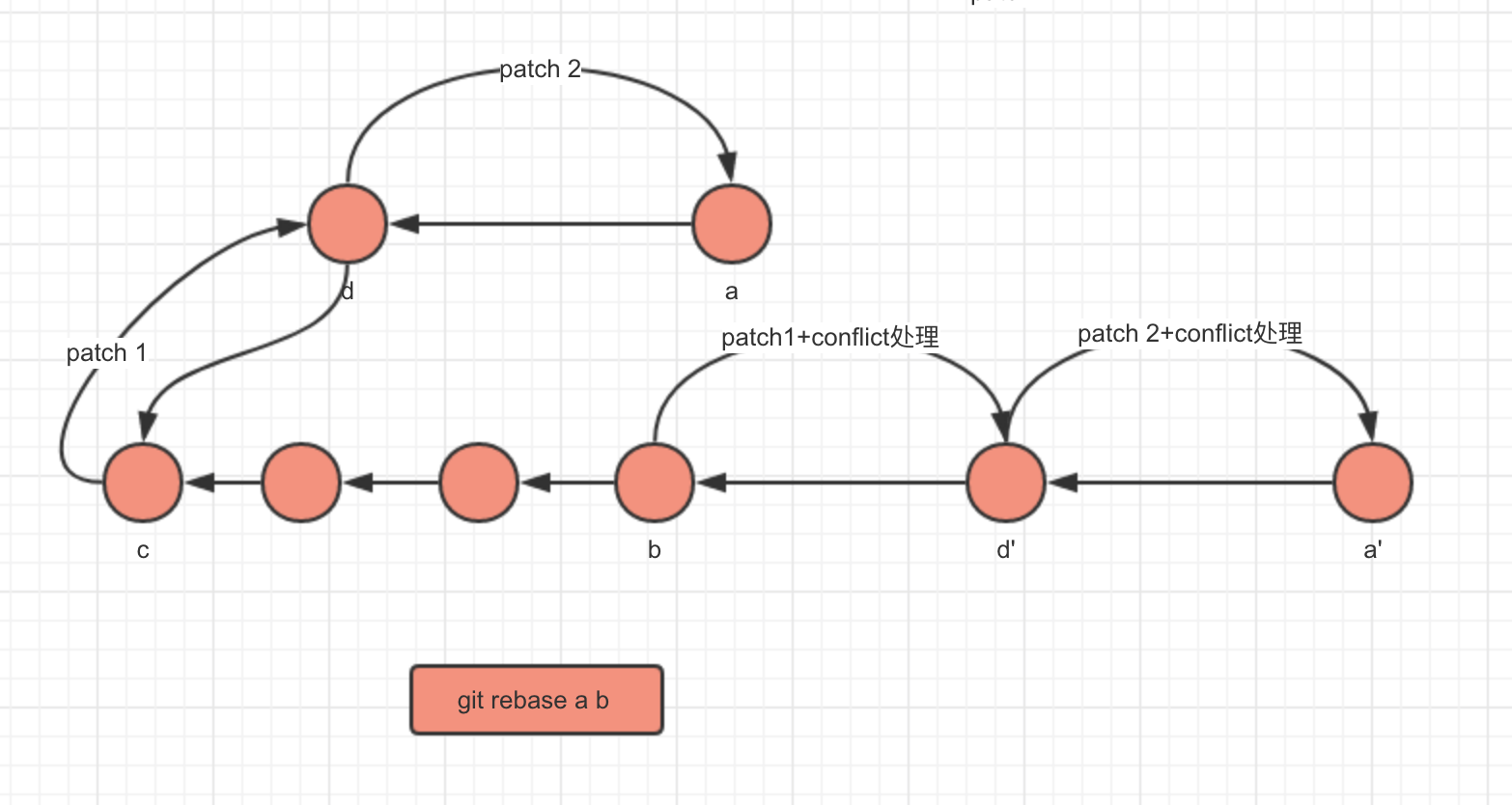
git rebase
1.找到a和b的公共父节点c
2.将b位于c之后的commit一个一个cherry-pick到a。(cherry-pick一次就可能产生一次conflict)
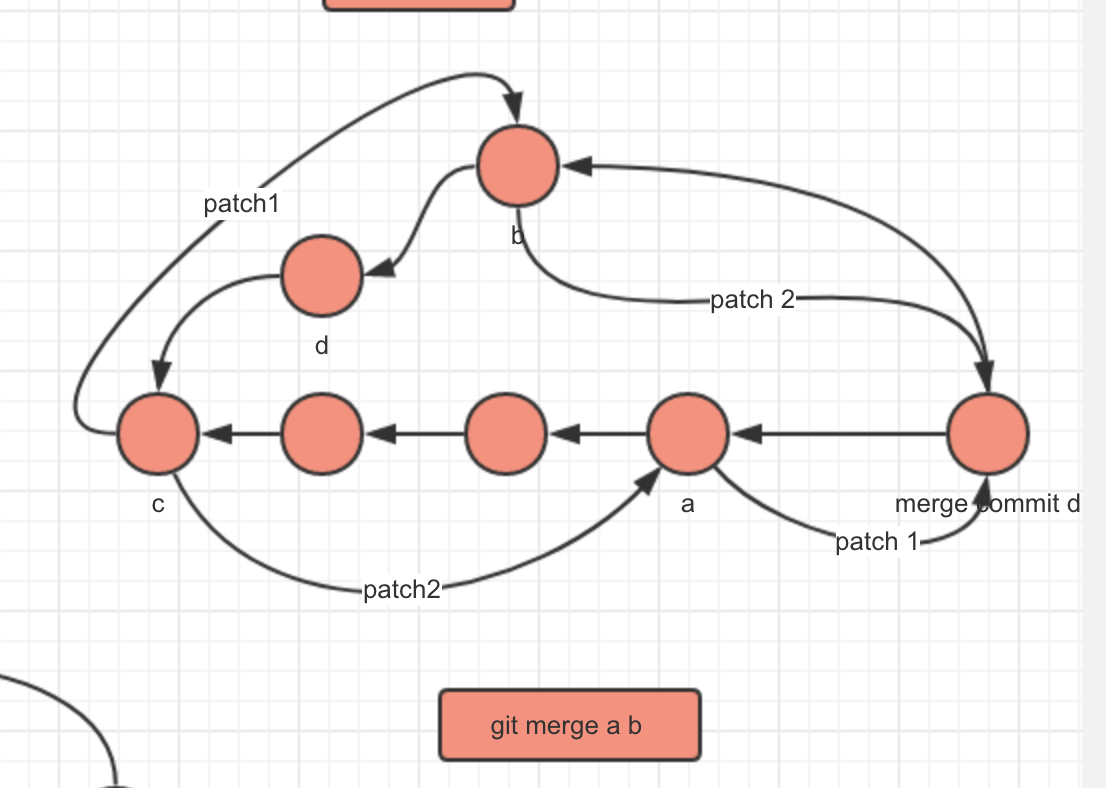
git merge
1.diff a、b的公共父节点c和b,生成patch文件。
2.将patch文件apply到a,生成一个merge commit(d)。(同理cherry-pick,这一步是会产生conflict的)
3.将当前HEAD指向d,d的父commit指向a、b。(你会发现git diff d和a,可以得到代表c到b的修改的patch文件,git diff d和b,可以得到代表c到a修改的patch文件,因此我们可以恢复到merge前a,b任何一个commit)
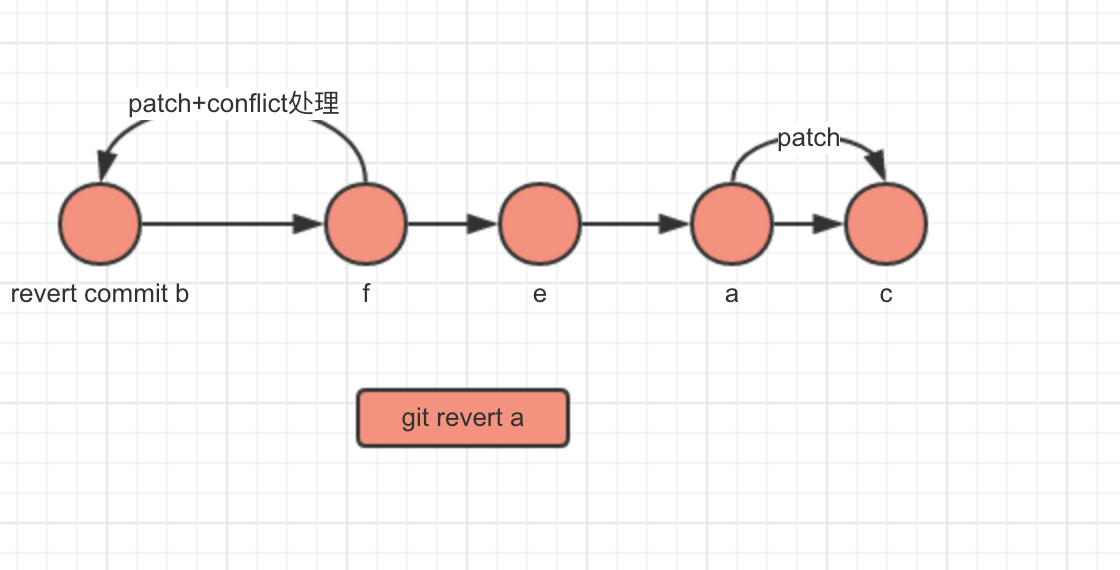
git revert
1.diff a的父commit(如果a是一个merge commit,会有两个父commit,此时需要指定恢复到哪一个commit)与a,得到patch文件。
2.将patch文件apply到HEAD,生成一个revert commit(b)。
3.b的父commit指向HEAD,将HEAD指向b。
git reset
1.diff a和HEAD,得到patch文件。
2.根据patch文件与a的tree在暂存区生成blob对象。
3.HEAD与branch的指针都指向a。

Comments